这是笔者学习大模型微调的第一篇笔记。本着从易到难,循序渐进的原则,第一步先尝试通过现有的数据集和微调服务平台完成一个小demo,初步了解整个微调的流程。
微调平台
本文中将要使用的是硅基流动提供的模型微调服务。
数据准备
在这里可以下载到一组基于满血DeepSeek-R1产生的,带<think></think>标签的深度思考数据。该数据集的后缀是jsonl,这是一种在AI领域常用的文件类型,文件包含多行,每行内容都是一个json对象。
我们下载的这个数据集遵循alpaca格式(alpaca和sharegpt是最常用的两种微调数据格式,这里可以找到介绍),但硅基流动使用的是基于多轮对话的微调数据。
1. 每行是一个独立的 JSON 对象;
2. 每个对象须包含一个键名为 messages 的数组,数组不能为空;
3. messages 中每个元素必须包含 role 和 content 两个字段;
4. role 只能是 system、user 或 assistant;
5. 如果有 system 角色消息,应在数组首位;
6. 第一条非 system 消息必须是 user 角色;
7. user 和 assistant 角色的消息应当交替、成对出现,不少于 1 对;
所以我们需要写一个简单的脚本来对数据进行处理。
import sys
import json
fin = open(sys.argv[1], 'r', encoding='utf8')
fout = open(sys.argv[2], 'w+', encoding='utf8')
for i, line in enumerate(fin.readlines()):
obj = json.loads(line)
target = {
'messages': [
{'role': 'user', 'content': obj['instruction']},
{'role': 'assistant', 'content': obj['output']}
]
}
fout.write(json.dumps(target, ensure_ascii=False))
fout.write("\n")
fin.close()
fout.close()
将该文件保存为alpaca2siliconflow.py,并执行下面的命令来将下载好的distill_r1_110k_sft.jsonl
转换为distill_r1_110k_sft_messages.jsonl。
$ python3 alpaca2siliconflow.py distill_r1_110k_sft.jsonl distill_r1_110k_sft_messages.jsonl
这样转换得到的数据集总共有约11万条。然而硅基流动的微调服务仅支持提交最多5千行数据。所以我们需要自行根据需要对数据集进行删减。
以这个数据集中每条数据的平均大小来估算的话,在硅基流动微调Qwen2.5-7b-Instruct,每一千条数据大概需要付14元钱左右。读者可以根据自己的情况酌情删减数据集。
上传数据集并开始微调
阅读这里的硅基流动微调文档,并在微调页面中单击新建微调任务来上传数据集并创建微调任务。这里我们选择对通义千问2.5的7B版本进行微调。创建成功后将可以看到下图的界面。
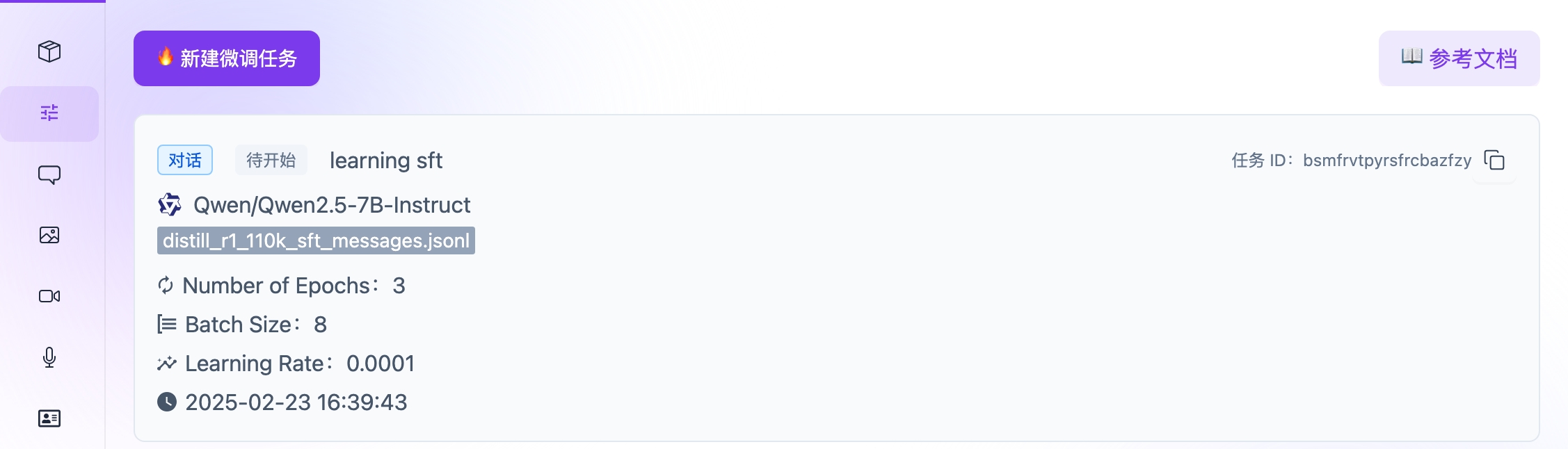
之后等待即可,在任务页面刷新可以看到任务状态。由于我只给了两千条数据,因此时间还是比较快的,大约20分钟左右微调过程就结束了。此时再次刷新刚才的微调页面就可以看到已经完成的微调任务和信息。
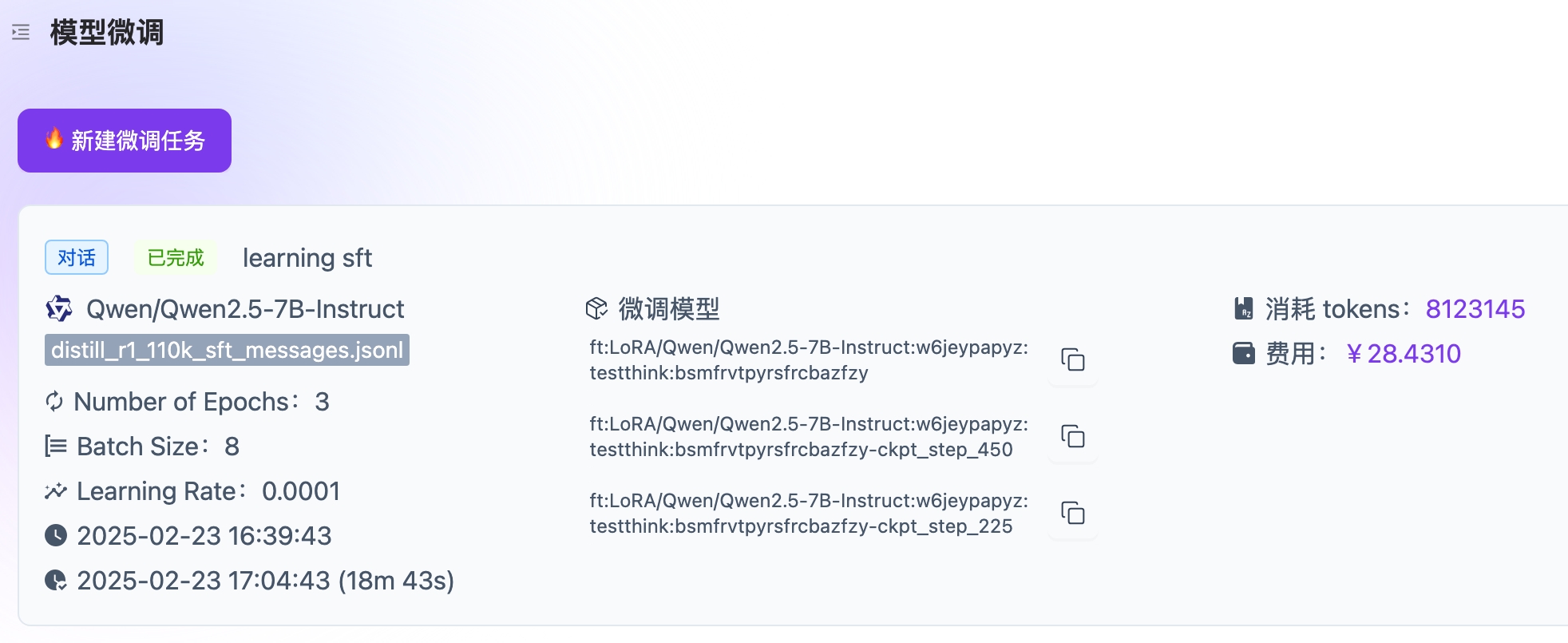
可以看到,我们的微调过程总共进行了3个epoch。因此在微调结果中就可以看到3个微调模型,分别是第1个,第2个和最后一个epoch结束之后的模型的checkpoint。关于在不同数据集下微调的Epoch的次数,可以参考Epoch的一些分析,但这里我们纯粹只是使用了硅基流动推荐的默认值。
这些模型的checkpoint均可以直接作为推理请求中的模型名来使用。比如我们原本使用Qwen/Qwen2.5-7B-Instruct这个模型名来调用通义千问2.5的原始模型,那么现在我们就使用ft:LoRA/Qwen/Qwen2.5-7B-Instruct:w6jeypapyz:testthink:bsmfrvtpyrsfrcbazfzy来作为模型名,即可访问微调之后得到的模型。
验证微调结果
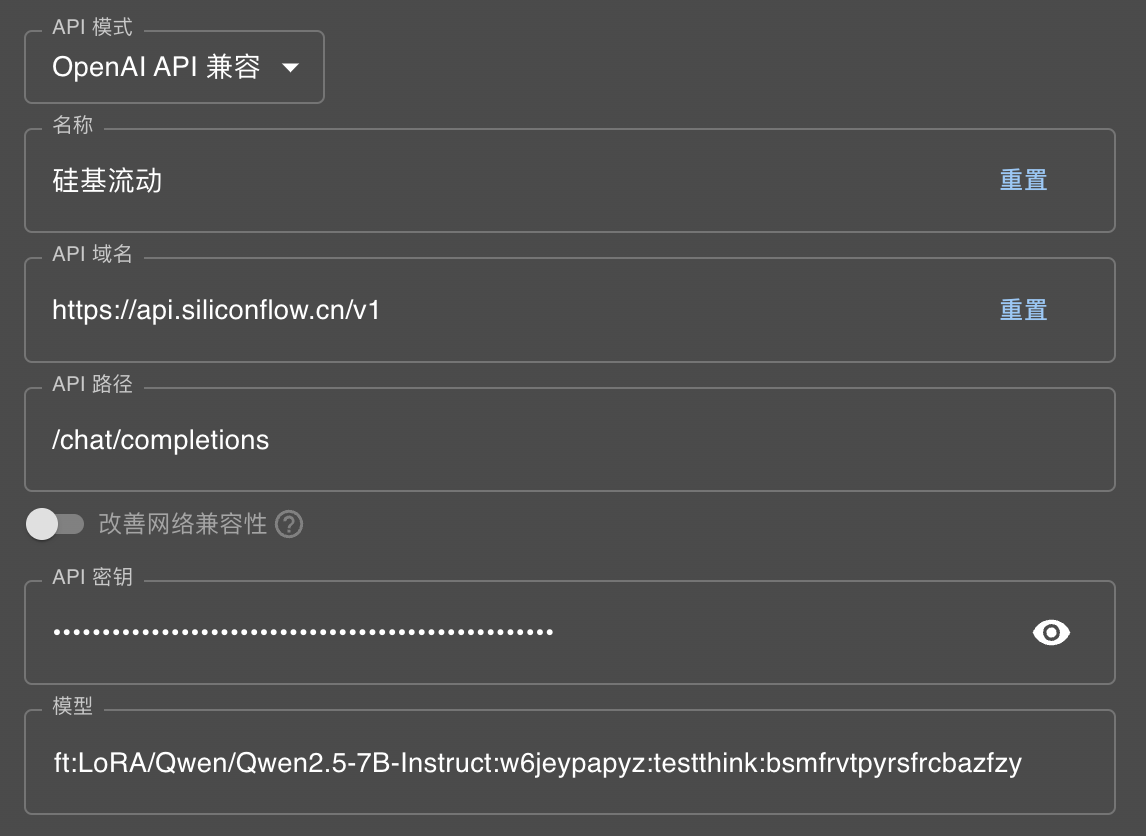
接下来我们用ChatBox来验证一下微调模型的效果。在ChatBox中按照刚才说的模型名来配置一下API。
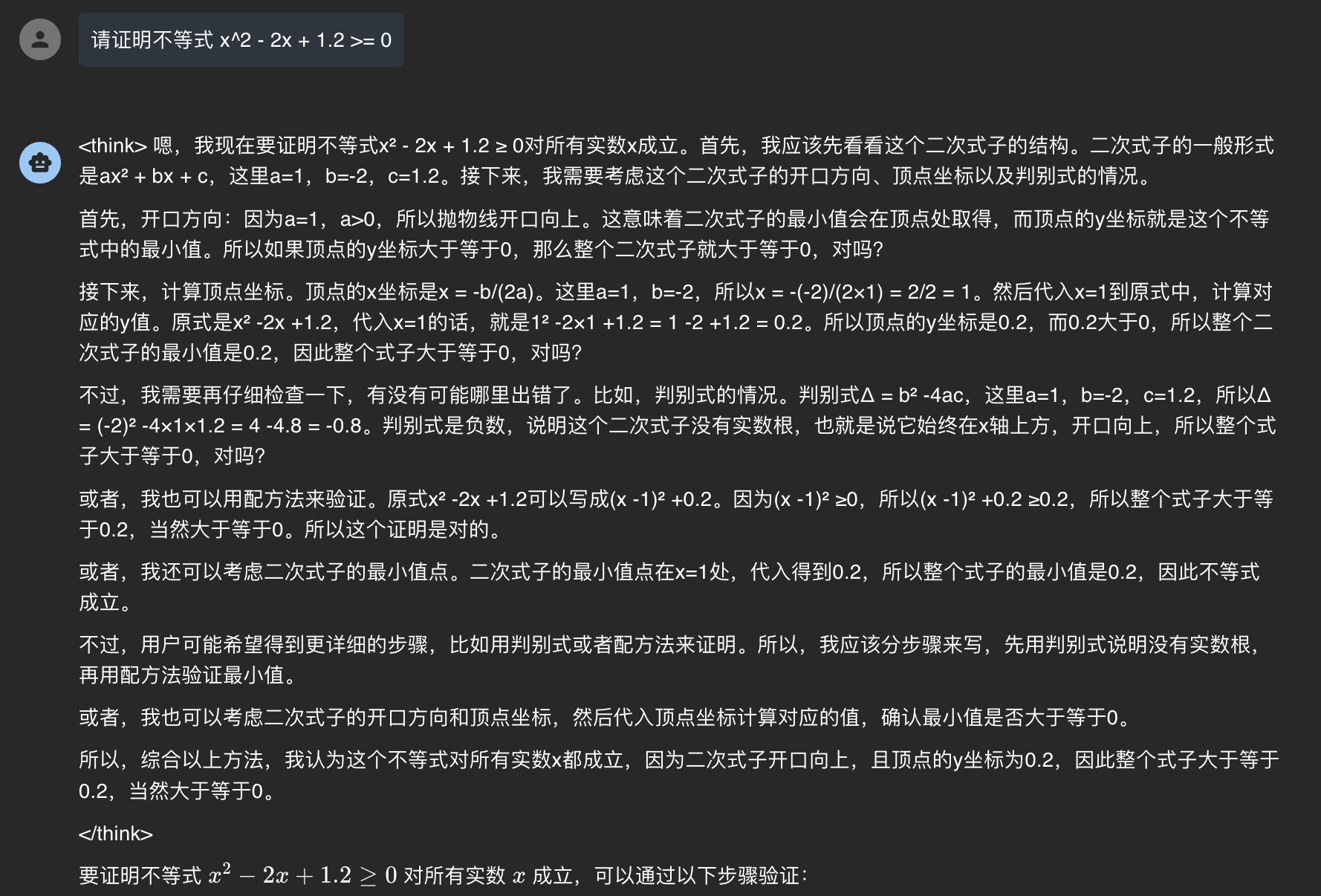
接下来我们提问一个简单的数学证明题,发现微调后的模型确实具备了在<think>标签中输出思维链的能力。
对比原始模型,Qwen2.5-7B-Instruct模型对于同一个问题的输出如下:
